大模型时代
AI Intelligence Revolution
Transformer Architecture
2017年Google提出的Transformer架构彻底改变了AI领域,其核心的自注意力机制让机器第一次学会了"注意力"
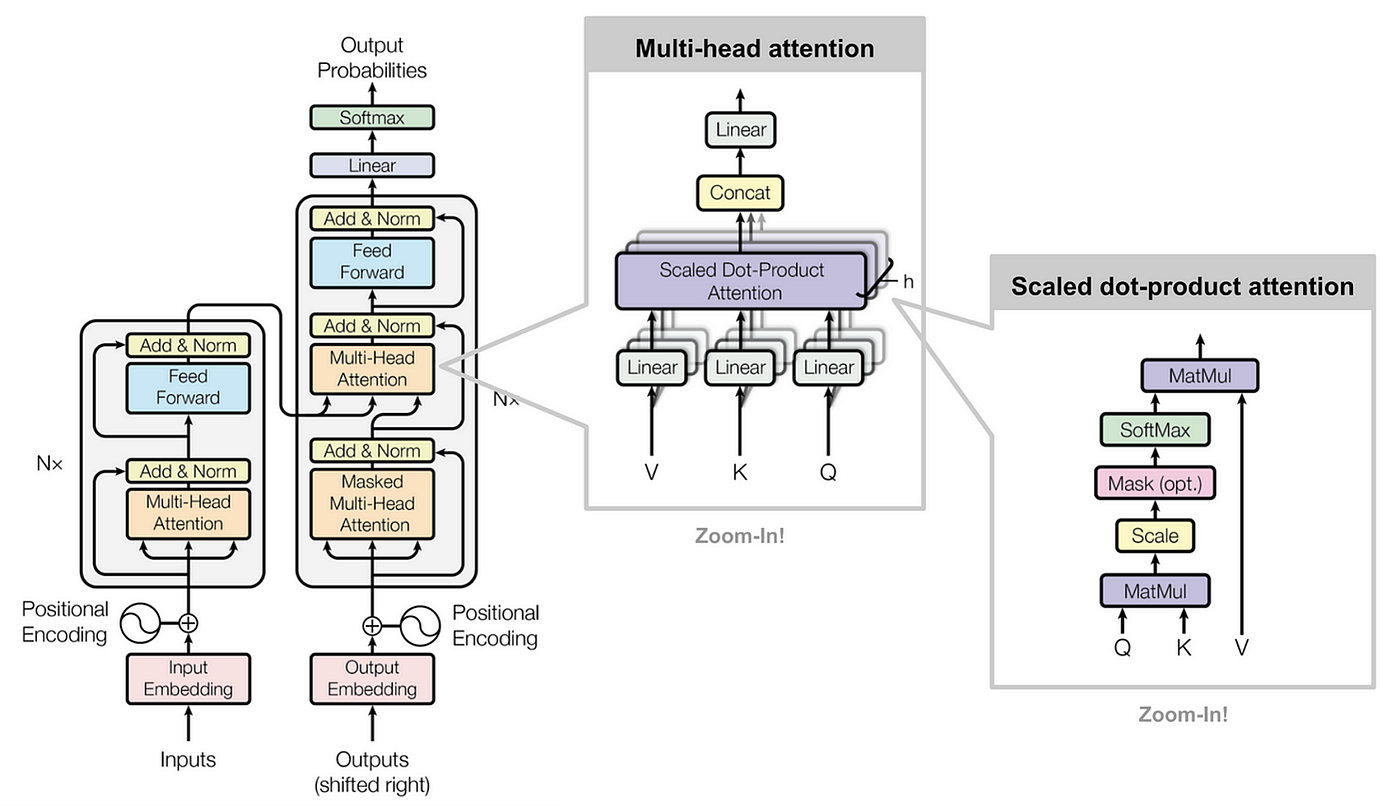
Self-Attention Mechanism
让AI模型能够同时关注输入序列中的所有位置,并根据它们之间的关系来权衡重要性
Multi-Head Attention
多头注意力机制允许模型同时关注不同类型的信息,提高理解能力
Parallel Processing
并行处理能力大幅提升训练效率,突破了传统RNN的序列处理限制
Long-Range Dependencies
有效处理长距离依赖关系,让AI能够理解更复杂的语言结构
主流大模型全面对比
2025年AI军备竞赛激烈,各大科技巨头竞相发布突破性模型
核心规格对比
| 模型 | 参数规模 | 上下文窗口 | 输入价格(/M tokens) | 输出价格(/M tokens) | 发布时间 | 开源状态 |
|---|---|---|---|---|---|---|
| GPT-4.5 | 12.8T | 128K | $75 | $150 | 2025-02 | ❌ |
| OpenAI O3 | 未公开 | 200K | $10 | $40 | 2025-04 | ❌ |
| Claude Opus 4 | 未公开 | 200K | $15 | $75 | 2025-01 | ❌ |
| Claude Sonnet 4 | 未公开 | 200K | $3 | $15 | 2025-01 | ❌ |
| Gemini 2.5 Pro | 未公开 | 2M | - | - | 2025-03 | ❌ |
| Qwen3-235B | 235B/22B活跃 | 128K | 免费 | 免费 | 2025-01 | ✅ |
| DeepSeek R1 | 未公开 | 128K | 免费 | 免费 | 2025-01 | ✅ |
| Llama 3.1 405B | 405B | 128K | 免费 | 免费 | 2024-07 | ✅ |
| Mistral Large 2 | 123B | 128K | $3 | $9 | 2024-07 | ❌ |
| Grok 3 | 未公开 | 128K | - | - | 2024-12 | ❌ |
性能基准测试对比
成本效益分析
模型深度解析
GPT-4.5
OpenAI最新的旗舰模型,拥有12.8万亿参数,专注于无监督学习的突破
核心能力
OpenAI O3
首个真正会"思考"的AI模型,在推理任务上表现突出
核心能力
Claude Opus 4
世界最佳编程模型,在SWE-bench上取得72.5%的突破性成绩
核心能力
Gemini 2.5 Pro
Google的多模态旗舰,拥有200万token的超大上下文窗口
核心能力
Qwen3-235B
阿里巴巴开源力作,采用MoE架构,22B活跃参数挑战顶级模型
核心能力
DeepSeek R1
中国开源推理模型,在数学和科学任务上表现卓越
核心能力
涌现能力:AI的意外惊喜
大模型最神奇的地方在于它们的"涌现能力"——这些能力并非人为设计,而是在模型规模达到某个临界点时突然出现的
In-Context Learning
模型能够从给定的几个例子中学会新任务,无需额外训练
Few-shot学习能力: 85%
Chain-of-Thought
通过步骤化思维推理,AI能够处理复杂的逻辑问题
推理能力提升: 92%
Code Generation
从自然语言描述自动生成高质量代码
代码生成准确率: 78%
Multilingual Understanding
跨语言理解和翻译能力的自然涌现
多语言支持: 88%
涌现能力研究发现
最新研究表明,这些所谓的"涌现能力"主要源于上下文学习、 模型记忆和推理能力的结合。 当模型规模达到临界点时,这些能力会突然显现,就像物理学中的相变现象。
多模态能力:AI开始"看见"世界
GPT-4V的发布标志着AI进入多模态时代,不仅能理解文本,还能分析图像、视频、音频

2025 AI Model Selection Guide
不同AI模型的最佳使用场景和能力对比
视觉理解
能够理解和分析图像内容,识别物体、场景、文本等
- • 图像描述和分析
- • OCR文字识别
- • 图表数据提取
- • 艺术作品解读
视频分析
处理动态视频内容,理解时序信息和运动模式
- • 视频内容摘要
- • 动作识别
- • 场景切换检测
- • 时间序列分析
音频处理
语音识别、音频分析和音乐理解能力
- • 语音转文字
- • 音乐分析
- • 情感识别
- • 多语言支持
技术挑战与未来展望
尽管大模型取得了巨大成功,但仍面临着幻觉、偏见、计算资源等现实挑战
AI幻觉问题
AI有时会生成看似合理但实际错误的信息,当前幻觉率约为1.3%-4.1%
幻觉率: 4.1%
解决方案:
- • 改进训练数据质量
- • 增强事实检查机制
- • 多模型验证方案
- • 实时知识更新
计算资源消耗
训练GPT-4.5需要数千个GPU运行数月,成本高达数千万美元
优化方向:
- • 模型压缩技术
- • 分布式训练
- • 专用AI芯片
- • 绿色计算
偏见与公平性
AI模型可能继承训练数据中的偏见,影响输出的公平性和准确性
改进措施:
- • 多样化训练数据
- • 偏见检测算法
- • 伦理AI框架
- • 人工审核机制
安全性与对齐
确保AI系统的行为与人类价值观保持一致,避免潜在风险
安全措施:
- • RLHF人类反馈强化学习
- • 宪法AI训练
- • 红队测试
- • ASL安全等级
2025年AI里程碑
2025年被认为是AI发展的关键年份,多个技术突破标志着我们正在迈向AGI时代
January 2025
Claude 4系列发布
Anthropic发布Claude Opus 4和Sonnet 4,其中Opus 4成为世界最佳编程模型, 在SWE-bench上达到72.5%的突破性成绩
February 2025
GPT-4.5重磅发布
OpenAI发布12.8万亿参数的GPT-4.5, 在无监督学习方面取得重大突破,幻觉率显著降低
March 2025
Gemini 2.5 Pro登场
Google发布Gemini 2.5 Pro,拥有200万token的超大上下文窗口, 多模态能力再次升级
April 2025
OpenAI O3突破AGI边界
O3在ARC-AGI测试中达到75.7%, 首次在通用智能测试中接近人类水平
May 2025
开源模型强势崛起
Qwen3和DeepSeek R1等中国开源模型展现出与闭源模型竞争的实力, 推动AI民主化发展
API实践指南
通过实际代码示例,学习如何使用OpenAI API和Google AI Studio构建AI应用
OpenAI API 快速入门
import openai
from openai import OpenAI
# 初始化客户端
client = OpenAI(api_key="your-api-key-here")
# 使用GPT-4.5进行对话
response = client.chat.completions.create(
model="gpt-4.5",
messages=[
{
"role": "system",
"content": "你是一个专业的AI助手,擅长解释复杂的技术概念"
},
{
"role": "user",
"content": "请解释什么是Transformer架构"
}
],
max_tokens=1000,
temperature=0.7
)
print(response.choices[0].message.content)
Google AI Studio 使用示例
import google.generativeai as genai
# 配置API密钥
genai.configure(api_key="your-gemini-api-key")
# 初始化Gemini 2.5 Pro模型
model = genai.GenerativeModel('gemini-2.5-pro')
# 多模态输入示例
response = model.generate_content([
"分析这张图片中的内容",
{
"mime_type": "image/jpeg",
"data": image_data
}
])
print(response.text)
# 长文档处理示例
long_document = """
[超长文档内容...]
"""
response = model.generate_content(
f"请总结以下文档的主要观点:\n\n{long_document}"
)
print(response.text)
Claude API 调用示例
import anthropic
# 初始化Anthropic客户端
client = anthropic.Anthropic(
api_key="your-claude-api-key"
)
# 使用Claude Opus 4进行代码生成
response = client.messages.create(
model="claude-opus-4",
max_tokens=2000,
temperature=0.3,
messages=[
{
"role": "user",
"content": "请帮我写一个Python函数,实现快速排序算法"
}
]
)
print(response.content[0].text)
# 使用思考模式
response = client.messages.create(
model="claude-opus-4",
max_tokens=4000,
temperature=0.7,
messages=[
{
"role": "user",
"content": "请详细分析这个算法的时间复杂度和空间复杂度"
}
],
extra_headers={"anthropic-thinking": "true"}
)
print(response.content[0].text)
交互式AI演示
体验AI模型的实时对话能力